Logic Programming with Pytholog
Getting Started
Installation
pip install pytholog
import pytholog as pl
Defining a knowledge base object to store the facts and rules.
new_kb = pl.KnowledgeBase("flavor")
new_kb(["likes(noor, sausage)",
"likes(melissa, pasta)",
"likes(dmitry, cookie)",
"likes(nikita, sausage)",
"likes(assel, limonade)",
"food_type(gouda, cheese)",
"food_type(ritz, cracker)",
"food_type(steak, meat)",
"food_type(sausage, meat)",
"food_type(limonade, juice)",
"food_type(cookie, dessert)",
"flavor(sweet, dessert)",
"flavor(savory, meat)",
"flavor(savory, cheese)",
"flavor(sweet, juice)",
"food_flavor(X, Y) :- food_type(X, Z), flavor(Y, Z)",
"dish_to_like(X, Y) :- likes(X, L), food_type(L, T), flavor(F, T), food_flavor(Y, F), neq(L, Y)"])
Note that neq() is pytholog's way to apply inequality so here "neq(L, Y)" means L != Y meaning that we look for new dishes not the one already liked by the person in the query.
OR can be implemented with defining the rules as many times as the OR facts. For example, to say "fly(X) :- bird(X) ; wings(X)." can be defined as two rules as follows: "fly(X) :- bird(X)." and "fly(X) :- wings(X)."
Let’s do some queries in this database using its facts and rules.
new_kb.query(pl.Expr("likes(noor, sausage)"))
# ['Yes']
new_kb.query(pl.Expr("likes(noor, pasta)"))
# ['No']
Memoization
I added Memoization to speed up the queries.
Wikipedia definition: In computing, memoization or memoisation is an optimization technique used primarily to speed up computer programs by storing the results of expensive function calls and returning the cached result when the same inputs occur again.
Let’s test it doing the same query twice and compare time used to do the query.
# query 1
from time import time
start = time()
print(new_kb.query(pl.Expr("food_flavor(What, sweet)")))
print(time() - start)
# [{'What': 'limonade'}, {'What': 'cookie'}]
# 0.0020236968994140625
# query 2
start = time()
print(new_kb.query(pl.Expr("food_flavor(Food, sweet)")))
print(time() - start)
# [{'Food': 'limonade'}, {'Food': 'cookie'}]
# 0.0
As you see, it took almost no time to return the same answer again and it also takes care of different Uppercased variable inputs as they anyways will be the same result no matter what they are.
Nested rules
Now we will use the dish_to_like rule to recommend dishes to persons based on taste preferences.
start = time()
print(new_kb.query(pl.Expr("dish_to_like(noor, What)")))
print(time() - start)
# [{'What': 'gouda'}, {'What': 'steak'}]
# 0.001992940902709961
Let’s test the Memoization again:
start = time()
print(new_kb.query(pl.Expr("dish_to_like(noor, What)")))
print(time() - start)
# [{'What': 'gouda'}, {'What': 'steak'}]
# 0.0
Constraint Satisfaction Problem
City Coloring problem
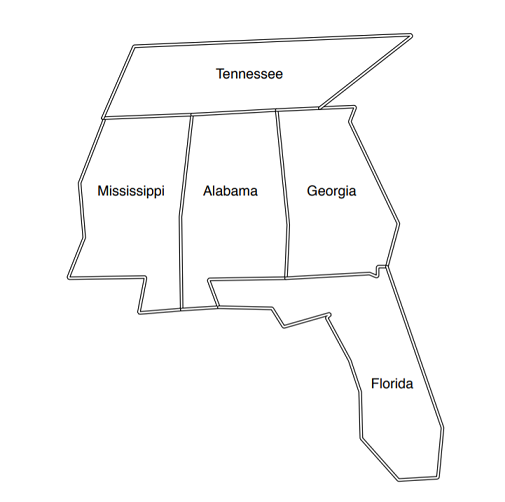
Image source: Seven Languages in Seven Weeks Book
The problem is Constraint Satisfaction Problem. The problem is to color each city using only three colors but no adjacent cities can be colored the same. The problem might seem so easy but it’s really challenging how to tell this to a machine. But using prolog logic it is kind of easier because all you have to do is to specify the rules of the problem and prolog will answer.
## new knowledge base object
city_color = pl.KnowledgeBase("city_color")
city_color([
"different(red, green)",
"different(red, blue)",
"different(green, red)",
"different(green, blue)",
"different(blue, red)",
"different(blue, green)",
"coloring(A, M, G, T, F) :- different(M, T),different(M, A),different(A, T),different(A, M),different(A, G),different(A, F),different(G, F),different(G, T)"
])
Let’s query the answer:
## we will use [0] to return only one answer
## as prolog will give all possible combinations and answers
city_color.query(pl.Expr("coloring(Alabama, Mississippi, Georgia, Tennessee, Florida)"), cut = True)
# {'Alabama': 'blue',
# 'Mississippi': 'red',
# 'Georgia': 'red',
# 'Tennessee': 'green',
# 'Florida': 'green'}
Probabilistic Logic
Now let's try to play with some probabilities. First in prolog "is" is used to assign the result of operations. For example, if we want to say "A = 3 * 4", we say "A is 3 * 4", not "A = 3 * 4" because this is unification not assignment.
Let's define some dummy knowledge base with probabilities and query them: The numbers are totally dummy and have no meanings just to explain the functionality.
battery_kb = pl.KnowledgeBase("battery")
battery_kb([
"battery(dead,P) :- voltmeter(battery_terminals,abnormal,P2), P is P2 + 0.5",
"battery(dead,P) :- electrical_problem(P), P >= 0.8",
"battery(dead,P) :- electrical_problem(P2), age(battery,old,P3), P is P2 * P3 * 0.9",
"electrical_problem(0.7)",
"age(battery,old, 0.8)",
"voltmeter(battery_terminals,abnormal,0.3)"])
battery_kb.query(pl.Expr("battery(dead, Probability)"))
# [{'Probability': 0.8}, {'Probability': 'No'}, {'Probability': 0.504}]
# the second one is "No" because the condition has not been met.
Rules from Machine Learning
Taking rules from Machine Learning model and feed them into knowledge base then try to predict new instances.
This shows beneficial for Explainable AI. One can explain why a model predicts specific prediction.
Let's suppose that we have these rules from a Decision Tree Model to classify iris flowers. And we have a new record for which we try to predict using the rules.
iris_kb = pl.KnowledgeBase("iris")
iris_kb([## Rules
"species(setosa, Truth) :- petal_width(W), Truth is W <= 0.80",
"species(versicolor, Truth) :- petal_width(W), petal_length(L), Truth is W > 0.80 and L <= 4.95",
"species(virginica, Truth) :- petal_width(W), petal_length(L), Truth is W > 0.80 and L > 4.95",
## New record
"petal_length(5.1)",
"petal_width(2.4)"])
Now let's try to predict the class:
iris_kb.query(pl.Expr("species(Class, Truth)"))
# [{'Class': 'setosa', 'Truth': 'No'},
# {'Class': 'versicolor', 'Truth': 'No'},
# {'Class': 'virginica', 'Truth': 'Yes'}]
Now let's extract the rules for some goal or fact.
iris_kb.rule_search(pl.Expr("species(Species, Truth)"))
# [species(setosa,Truth):-petal_width(W),TruthisW<=0.80,
# species(versicolor,Truth):-petal_width(W),petal_length(L),TruthisW>0.80andL<=4.95,
# species(virginica,Truth):-petal_width(W),petal_length(L),TruthisW>0.80andL>4.95]
So now we can see the rules why a model chooses a prediction and explain the behavior.
Helper Functions
clear_cache() is used to clean the cache inside the knowledge_base:
new_kb.clear_cache()
from_file() is used to read facts and rules from a prolog ,pl, or txt file:
example_kb = pl.KnowledgeBase("example")
example_kb.from_file("/examples/example.txt")
# facts and rules have been added to example.db
example_kb.query(pl.Expr("food_flavor(What, savory)"))
# [{'What': 'gouda'}, {'What': 'steak'}, {'What': 'sausage'}]
Also we can constructs rules or facts looping over dataframes:
import pandas as pd
df = pd.DataFrame({"has_work": ["david", "daniel"], "tasks": [8, 3]})
df
# has_work tasks
#0 david 8
#1 daniel 3
ex = pl.KnowledgeBase()
for i in range(df.shape[0]):
ex([f"has_work({df.has_work[i]}, {df.tasks[i]})"])
ex.db
# {'has_work': {'facts': [has_work(david,8), has_work(daniel,3)],
# 'goals': [[], []],
# 'terms': [['david', '8'], ['daniel', '3']]}}
Graph Traversals with Pytholog
Let's define a weighted directed graph and see if we can get a path, hopefully the shortest, between two nodes using breadth first search.
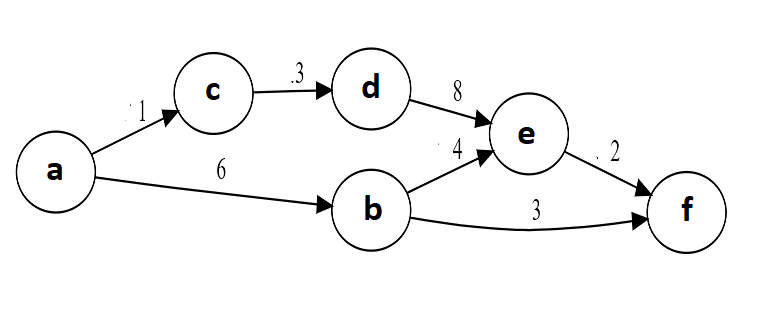
Image Source
graph = pl.KnowledgeBase("graph")
graph([
"edge(a, b, 6)", "edge(a, c, 1)", "edge(b, e, 4)",
"edge(b, f, 3)", "edge(c, d, 3)", "edge(d, e, 8)",
"edge(e, f, 2)",
"path(X, Y, W) :- edge(X , Y, W)",
"path(X, Y, W) :- edge(X, Z, W1), path(Z, Y, W2), W is W1 + W2"])
answer, path = graph.query(pl.Expr("path(a, f, W)"), show_path = True)
print(answer)
print([x for x in path if str(x) > "Z"])
# [{'W': 9}, {'W': 12}, {'W': 14}]
# ['d', 'b', 'e', 'c']
Now with the show_path argument we can see the nodes the search passed by and we can see it gave all the possible answers and the first one is the best. So let's use the cut argument to get only the first result and stop the search.
answer, path = graph.query(pl.Expr("path(a, e, W)"), show_path = True, cut = True)
print(answer)
print([x for x in path if str(x) > "Z"])
# [{'W': 10}]
# ['b']
Future implementation will try to come up with ideas to combine this technique with machine learning algorithms and neural networks
Contribution, ideas and any kind of help will be much appreciated